
[논문 리뷰] Conformer: Convolution-augmented Transformer for Speech Recognition
논문 링크는 여기!
** 아직 작성 중인 포스트로, 내용이 추가 및 수정 될 예정입니다.
🧚🏻♀️짧게 정리해보자면 . . .
Convolution은 Local feature를, Transformer는 Global interaction을 잘 파악한다는 장점을 가진다. 이때, Conformer는 convolution과 self-attention 두 구조를 결합하여 각 모델의 장점을 모두 수용하고자 했다.
| Introduction
Neural net 기반의 end-to-end Auto Speech Recognition (ASR) 시스템이 큰 발전을 보였다. 이때 주로 사용되는 모델은 RNN, Convolution, Transformer이다. 각 모델의 특징은 아래와 같다.
- RNN
- 오디오의 Temporal dependency를 잘 모델링한다
- Convolution
- Receptive field를 통해 local context를 잘 파악한다
- Global information을 얻기 위해서는 수많은 레이어와 파라미터, 즉 많은 연산량을 필요로 한다
- Transformer
- Global interaction을 잘 파악한다
- Local feature pattern을 파악하는 데에는 어려움을 보인다
특히 Convolution과 Transformer는 서로 상반되는 장단점을 가진다. 저자는 이 점에 집중했고, 두 모델을 결합하여 각각의 단점을 보완하는 모델을 만들고자 했다.
논문에서는 Global, Local information을 모두 잘 파악하고 활용하기 위해 Convolution과 Transformer 구조를 결합하는 새로운 방법을 제안한다. LibriSpeech 데이터 셋에 대해 실험을 진행하여 SoTA 성능을 달성했으며, 구조에 따른 부가적인 실험을 통해 요소 별로 성능에 미치는 영향을 알아보았다.
| Method - Conformer Encoder
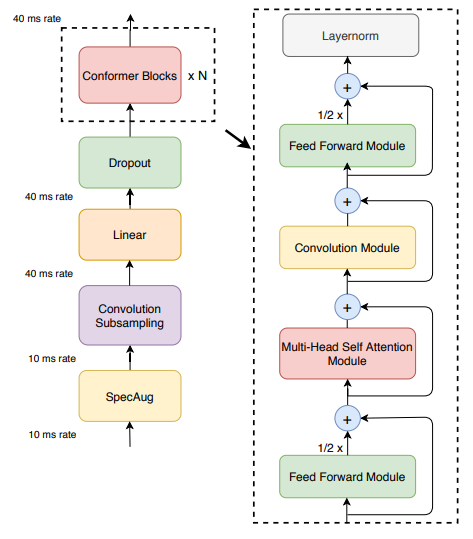
Conformer Encoder는 입력 시퀀스의 길이를 줄이면서도 중요한 정보는 보존할 수 있도록 하는 Convolution Subsampling layer와 제안 모델의 차별점인 Conformer Block을 통해 입력을 처리한다. Conformer Block은 Feed-forward module, Self-attention module, Convolution module로 이루어져 있다.
Multi-Headed Self-Attention module
Self-Attention과 Sinusoidal positional encoding을 함께 사용했다. 이러한 설계를 통해 입력의 길이에 상관없이 일반화 성능이 높아졌으며, 발화 길이에 상관없이 인코더가 강건해졌다.
Convolution module
Pointwise convolution - GLU - 1D depthwise convolution - batch norm 의 순서로 구성되어 있다.
🐨 Point-wise Convolution
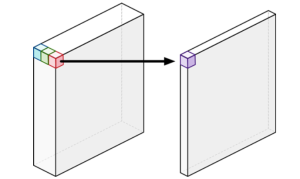
Point-wise Convolution은 1x1 convolution으로 입력의 각 채널에 대한 연산을 수행한다. 연산을 수행하면 Feature map의 크기는 유지되고, 채널의 수가 조절된다.
🐨 Depth-wise Convolution
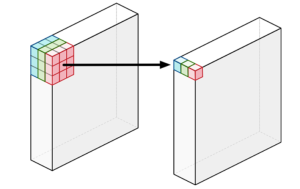
Depth-wise Convolution은 각 채널마다 따로 convolution 연산을 수행한다. 채널 별로 별도의 필터가 존재하며, 상호작용 없이 각각 특징을 추출한다. 연산을 수행하면 Point-wise convolution과 반대로, Feature map의 크기가 변경되고, 채널의 수는 유지된다.
Feed-Forward module
Transformer 모델과 동일한 linear layer - activation function - linear layer 구조에 residual connection을 적용했으며, re-norm residual unit, layer noramlization, swish activation 등을 추가했다.
Conformer Block
Conformer Block은 두 개의 Feed Forward module과 그 사이에 위치한 Multi-Headed Self-Attention Module, Convolution module로 이루어져 있다. Feed-forward module에는 half-step residual weight이 적용되어 다른 값들과 다르게 residual connection으로 반만 사용된다.
| Experiemnts
Data
LibriSpeech 데이터 셋에 대해 실험을 진행했다. 총 970 시간의 라벨링 된 데이터와 800M 개의 word token text-only corpus로 이루어진 이 데이터 셋에서 25ms의 길이로, 80개의 채널을 추출하여 사용했다. 데이터 증강을 위해 SpecAugment도 적용했다.
🐨 SpecAugment
논문에 따르면 입력되는 음성 데이터에 대해 증강 기법 중 하나인 SpecAugment를 적용했다. 기존에는 오디오에 특정한 값(노이즈)를 주입하거나 시간을 조절 하는 등의 방식을 통해 데이터를 증강했다면, SpecAugment에선 Time warping, Frequency masking, Time masking의 세 가지 기본 방법을 바탕으로 증강 기법을 제안했다. 이를 통해 과적합 문제를 과소적합으로 변환하였고, 일반화 성능을 높일 수 있었다고 한다.
🔗 참고한 블로그 : Kaen’s Ritus
Conformer Transducer
모든 Conformer 모델(large, medium, small)의 디코더로 하나의 LSTM-layer를 사용했으며, LibriSpeech에 대해 학습된 3-layer LSTM Language model도 함께 실험에 사용되었다.
Results
논문에서는 ContextNet, Transformer transducer, QuartzNet에 대해 결과를 비교했다. 이때 평가지표는 WER이다. 언어 모델 없이 실험했을 때에는 Conformer Transducer가 Transformer, LSTM 기반 모델을 비롯하여 비슷한 크기의 Convolution 모델까지 뛰어넘는 성능을 보여줬다. 언어 모델까지 포함했을 때에도 마찬가지로 기존 모델보다 좋은 성능을 보였다.
| Ablation Studies
모델의 각 요소가 성능에 어떠한 영향을 미치는지 확인하기 위해 Ablation study를 진행했다.
Conformer Block and Transformer Block
Conformer block은 Convolution block을 포함하고 있으며, 하나가 아닌 두 개의 Feed-forward network가 Convolution block을 감싸고 있다는 점에서 Transformer Block과 차이가 존재한다. 저자는 Conformer block의 구성 요소에 대해 파악해보고자 하나씩 그 요소들을 제거해가며 실험을 진행했다. 제거 된 순서는 SWISH with ReLU, Convolution sub-block, Macaron style FFN, Self-attention with Positional embedding이다.
실험 결과, Convolution sub-block과 Macaron-style FFN이 가장 효과적인 역할을 함을 알 수 있었고, SWISH activation은 Conformer 모델이 빠르게 수렴할 수 있또록 돕는다는 것을 확인했다.
Combinations of Convolution and Transformer Modules
- Depth-wise convolution \(\rightarrow\) Lightweight convolution
- Convolution - MHSA module \(\rightarrow\) MHSA module - Convolution
- 입력을 쪼개서 MHSA module과 Convolution module이 각각 처리하고 결과를 concat
원래 구조를 위의 세가지 형태로 변경하여 실험을 진행해 본 결과, 전부 성능이 하락하는 모습을 보였다고 한다.
Macaron Feed Forward Modules
Conformer는 두 개의 Feed-forward Module을 MHSA module과 Convolution module의 앞과 뒤에 위치시켜서 마카롱 모양으로 만들었으며, half-step residuals도 추가적으로 적용하고 있다. 이 때, 두 개의 Feed-forward Module을 single FFN으로 변경하거나 half-step residuals를 full-step residuals로 변경하면 성능이 하락하는 모습이 나타난다,
Number of Attention Heads
Self-Attention에서 attention head는 각각 서로 다른 부분에 집중함으로써 예측 성능을 높인다. 이에 논문에서는 attention head의 개수에 따라 정확도가 어떻게 바뀔지 알아보는 실험을 진행했고, 16개까지는 정확도가 높아진다는 결론을 얻었다.
Convolution Kernel Sizes
마지막으로 진행한 Ablation study는 Depth-wise convolution의 kernel size에 따른 차이를 알아보기 위해 진행되었다. 3,7,17,32,65 중 하나를 커널 사이즈로 선정하여 모든 레이어에 동일하게 적용하였다. 실험 결과, 17이나 32까지는 결과가 좋아졌지만, 65에서부터는 성능이 하락되는 모습이 나타났다.
| Conclusion
이 논문에서는 CNN과 Transformer의 구성 요소를 결합하여 end-to-end speech recognition을 위한 새로운 구조인 Conformer를 발표했다. Ablation study를 통해 Conformer를 이루는 요소들의 중요성도 알아보았다.
댓글남기기